https://arxiv.org/pdf/2104.00620.pdf
TradeR: Practical Deep Hierarchical Reinforcement Learning for TradeExecution
논문을 읽다가 우선적으로
계층적 강화학습 에 대해서 찾아보게 되었다.
계층적 강화 학습이란?
참조 ( https://bluediary8.tistory.com/4 )
Hierarchical Deep Reinforcement Learning (HDQN)
본 포스팅은 기본적은 강화학습인 Q-learning과 DQN(Deep Q-network)에 대해 알고 있으셔야 읽기 수월합니다. Q-learning과 DQN에 대한 내용은 김성교수님의 모두를 위한 RL 강의를 참고하시기 바랍니다. (http
bluediary8.tistory.com
여러 목표를 정해 그 목표를 차근차근 해결해 나가는 것
굳이 여러 목표를 통해 강화학습을 진행하느 이유는 , sparse reward (delayed reward ) 문제 때문
- Controller: 각 goal 내에서 reward가 최대가 되도록 학습 (goal을 달성할 수 있도록) 하는 DQN 모형
- Actiondms controller에서만 수행됨. meta controller는 단지 controller에게 goal을 할당
- Meta-controller: Episode의 총 reward가 커지도록 (게임을 clear 할 수 있도록) 하는 goal을 찾아내는 DQN 모형
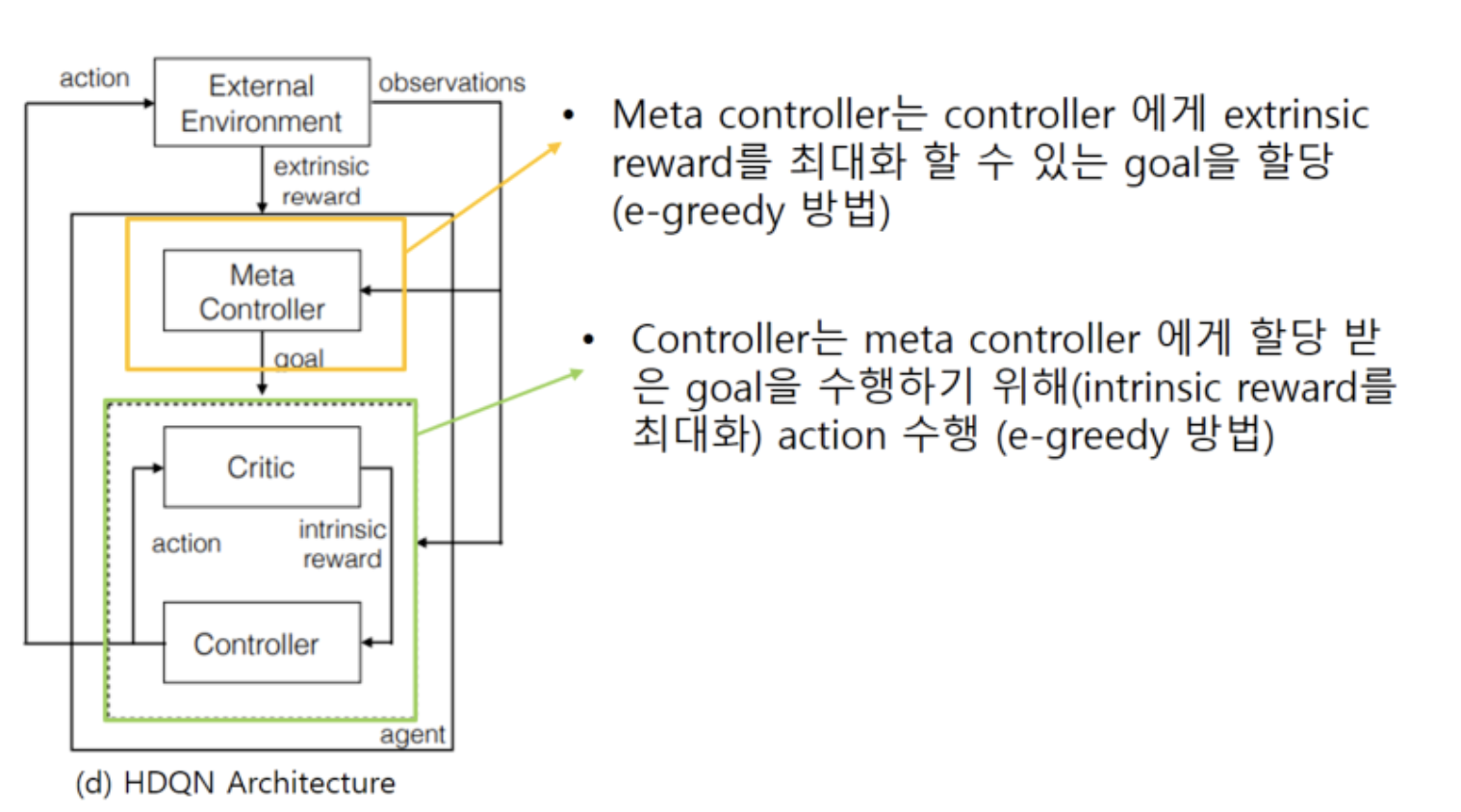
Meta controller는 controller에게 목표를 할당하고(e-greedy방법으로) controller는 할당받은 goal을 수행하기 위해 (intrinsic reward를 최대화) 하기 위해 action을 수행하고 보상을 받고 학습을 진행함.
각 controller의 Q-value function입니다. 일반적인 DQN의 Q-value function과 유사 함. 다만 reward가 다른점, controller에게만 action이 있다는 점과 각 controller의 state의 index만 주의하면 됨. 학습하는 과정은 DQN과 거의 유사함
'ReinforcementLearning' 카테고리의 다른 글
| [논문리뷰]Diversity is all you need: Learning skills without a reward function (0) | 2023.04.03 |
|---|---|
| meta-learning + RL (0) | 2023.04.03 |
| [ppo]Proximal policy optimization algorithms (0) | 2023.04.03 |
| [Book][doit_1]강화학습이란 (0) | 2023.04.03 |
| 블랙박스 최적화 알고리즘 이해하기 (0) | 2023.04.02 |

